

Yabble Allows Users to Create Custom Synthetic Data

Contents
You asked for it – and Yabble Virtual Audiences has delivered! Introducing proprietary data for Virtual Audiences. Here’s what’s new...
Upload your own data to an augmented data project in Yabble
Yabble users can now upload their own proprietary datasets to their Virtual Audiences projects in the Yabble platform. Simply define your topic, upload any relevant proprietary data in any combination of PDF, DOCX, TXT, XLSX or CSV formats, and have this inform the context of your target audience and their responses. This feature cleans and summarizes your proprietary data to work alongside Yabble’s publicly available data sources and generate personas, survey questions, and insights with your business-specific data as context.
Generate synthetic personas built from the combination of your own data and market context
Access to proprietary data means that Virtual Audiences can generate synthetic personas that are even more relevant to your core segments than ever before. The combination of up-to-the-minute market data alongside business-specific proprietary data results in persona generation that shows unparalleled relevance to your topic of choice and leads to insights that are even more actionable and pertinent than ever.
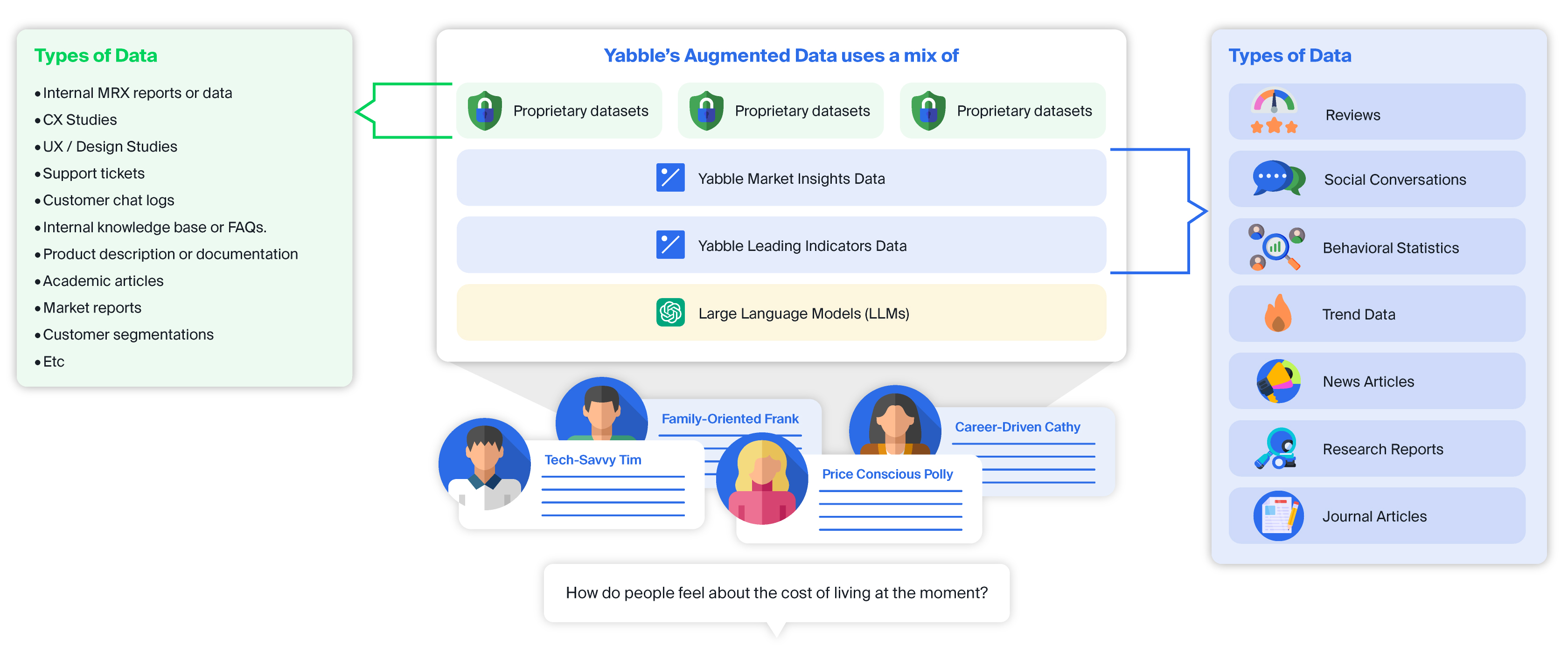
Gather insights and current trends with the context of your existing business data
In a world where data is king and access to data is queen, having Virtual Audiences that consistently and accurately reflect your customer segments is a game-changer. You can go from business question to actionable insight in minutes – now with your business’ unique context incorporated.
Click here to find out more about Virtual Audiences and explore our FAQs.
If you haven’t already tried Virtual Audiences out for yourself, book a demo with the Yabble team today to see how it could work for your insights needs.
Proprietary data for Virtual Audiences FAQs
What are some examples of good ‘proprietary data’ that I can use with Virtual Audiences?
To get the most out of the proprietary data feature of Virtual Audiences, types of data best suited to the tool:
-
Internal market research data or reports e.g. survey data, reports, interview transcripts etc
-
CX Studies
-
UX / Design Studies
-
Support tickets
-
Customer chat logs
-
Internal knowledge base or FAQs.
-
Product description or documentation
-
Academic articles
-
Market reports
-
Etc i.e. Any type of text data not available publicly on the internet that can better inform your specific project.
Where possible, provide data in string format i.e. data labels rather than numeric codes.
Can I upload multiple files types at once?
Yes! You can upload up to 10 files (max file size 2MB each) to one Virtual Audiences project, and they do not need to be the same file type.
What types of files can I upload?
There are several different file types that the Yabble proprietary data feature accepts, including .PDF, .CSV, .TXT, .DOCX, and .XLSX (max file size 2MB each).
How long will it take my data to process?
Virtual Audiences projects can take as little as 15 minutes to complete from topic input to insights output – but this will vary based on the quantity and size of the proprietary data you upload to the project i.e. the more data you provide, the longer the process will take for the AI to read and process the data.
How much does my proprietary data come into play vs. synthetic data?
When creating the Knowledge Lake for your Virtual Audience the AI will read across all data provided.
The extent to which it ‘relies’ on your proprietary data to create its personas, synthetic respondents and answers will vary depending on your data volume, content, completeness and the relevance of your data to the questions you have have asked. As well as the recency of your data.
As all data is multi dimensional, some data is more valuable to the process then other pieces, and this is decided by the AI on a case by case basis depending on the research or business question you have asked. Also the ability for the data to be cross referenced / validated between sources.
Yabble will always create the Knowledge Lake using a combination of sources, but the utilization rate of each source will vary dynamically depending on the question being asked.
Yabble’s AI also has a recency bias inherent – so, as an example, if the proprietary data you upload is from 3 years ago, the AI may find more recent information from our other sources.
If you have any specific questions about Virtual Audiences and how this works with your own data to provide insights, contact the team at support@yabble.com.
How relevant does the topic need to be to the proprietary data? What happens if the data is irrelevant?
Yabble’s AI will read across all data provided. It is assumed that you will provide data that is related to the topic, however, if there is some unrelated data, the AI will be able to ‘clean and ignore' this data to an extent.
As the product is in beta, edge cases where data is entirely unrelated may provide poor results.
If you have any specific questions about Virtual Audiences and how this works with your own data to provide insights, contact the team at support@yabble.com.
Can I do a Virtual Audiences project entirely run on proprietary data
No, not at this stage.
Can I customize the weight I give my proprietary data vs. other sources that are used?
No, not at this stage.
What if I don't have any demographic data for my proprietary data?
If your data doesn’t include any demographic data, the Yabble AI will recommend and generate target demographics, based on data it has gathered from other sources. This can always be regenerated later by you before you complete the project, if you would like to.
Note: The proprietary data will still be used to form the persona’s personality characteristics and behavior even if demographics are absent.
If I put my target audience as ages 18 – 45 but my data includes ages 18 – 65, will it disregard the irrelevant data?
There will be demographic-specific insights and general insights in the proprietary data. Insights specifically relevant to the non-target audiences might be disregarded when generating insights. But, all the relevant information will still be used.
Can I re-use personas and/or go back to the same project and ask more questions?
No, not at this stage.
How does it deal with images that might be in proprietary data? i.e. if you're importing a PDF that is a report of some kind, can that be imported?
At this stage, the AI cannot process images. It can pull some context from text in tables, but it’s not seamless. At this stage, text data is best for all data qualitative or quantitative i.e. labelled data rather than numeric codes.
Can I link my Yabble-collected data to a Virtual Audience project?
No, not at this stage. You can however download the data from the platform, then upload it in the VA process.
Can I access my proprietary data for theme counting, summarization or to chat with Gen?
No, that would need to be uploaded separately via the normal ingestion process in Yabble.
Can I ask my personas about specific proprietary data that I've uploaded?
Currently, the proprietary data is used as a layer in Knowledge Lake and blended with other data Yabble collects. At this stage you will not be able to ask the AI-generated personas about specific data you have uploaded.
How does it look at close-ended data? e.g. survey data that talks about awareness of certain programs, customer satisfaction, etc.?
Currently Yabble can read closed ended data that is in string format i.e. data labels rather than numeric. It will look at the question for context i.e. The question must be clear for the model to understand the context of ‘Very satisfied’ for example.
If you have any specific questions about Virtual Audiences and how this works with your own data to provide insights, contact the team at support@yabble.com.